Visualising Tolkien

Why?
First and foremost, I am a huge fan of J.R.R. Tolkien's work. I have lost count of the number of times I have read Lord of the Rings
. But I had not read The Hobbit
or The Silmarillion
yet, and decided to put an end to that situation.
Prior to purchasing it, I read several reviews about The Silmarillion
. One of the reviewers argued that it was the hardest book to read because 'and' was the most used word in the book
. I wondered if that was the case. And if not, why is it that The Silmarillion
is so hard to read? And I can testify that it is definitely hard to read: I attempted to read it at least thrice past year, but I ended reading several other books instead, Lord of The Rings
again as well.
The classic graphs
To find out if 'and' is the most frequent word in The Silmarillion
, I wrote a simple program who counted how many times did each word appear in the book. This quickly contradicted the affirmation by that reviewer, since the most frequent word in The Silmarillion
is the, followed by and and of.
Obviously, as I had this program and it could analyse any text instantly, I thought that maybe I could analyse the other books: The Hobbit
and The Lord Of The Rings
. If I place all results side by side I may be able to deduct why 'The Silmarillion' is not as readable as the others
, I said to myself. So I did:
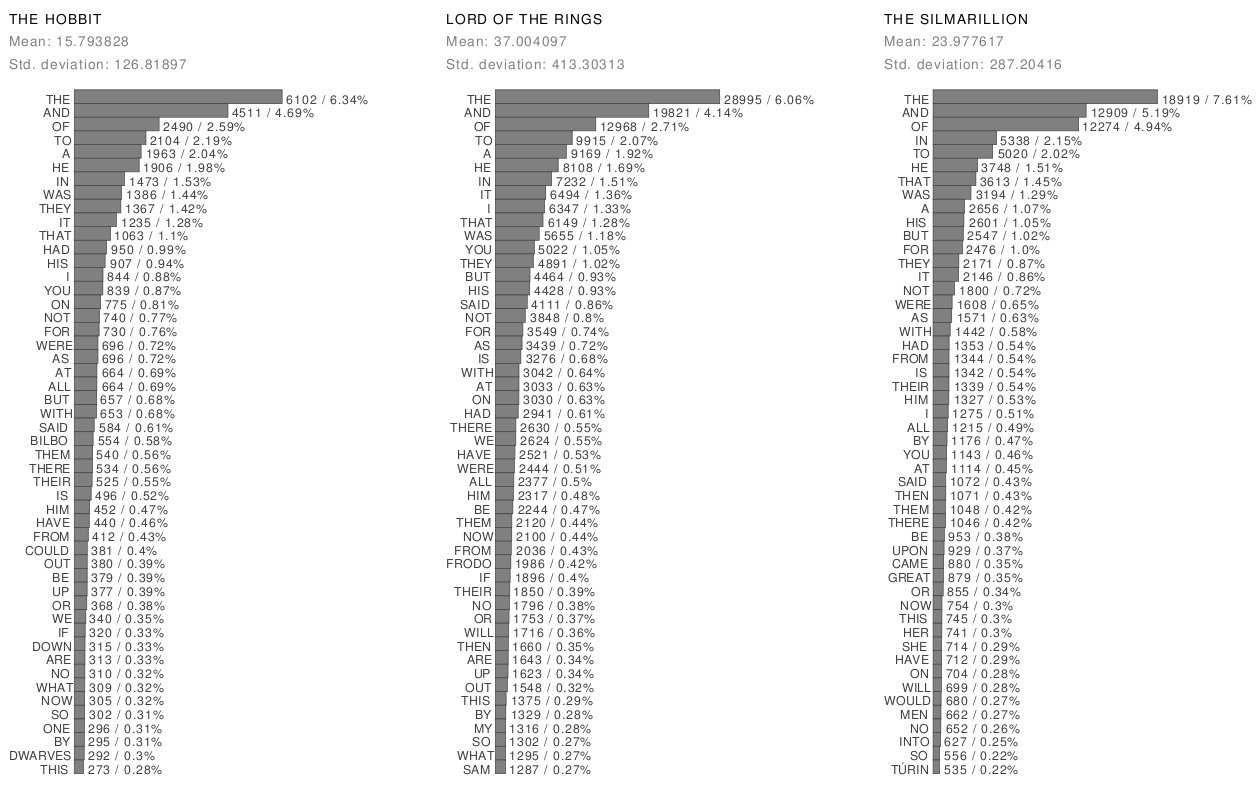
Interestingly enough, all three books share the same top three words. In fact, all of their top words are pretty much the same (the, and, of, in, to, he, that, ...). So it was totally unfair (apart from incorrect) to blame them for the lack of readability of a book.
What about the proportions and the distribution of words? If we compare the shapes of each chart together, it is easy to see that while the shapes for The Hobbit
and The Lord of The Rings
charts are really similar, the same does not occur with The Silmarillion
, where there is a huge quantitative difference between the top three words and the rest. Now that might explain something!
But I was not satisfied with this analysis yet. You cannot reduce style differences to numbers only; there were a number of factors that I had not considered yet: relations between words, typical constructions, language richness, even the length of the text itself! So I built a few more charts:

The word count chart confirms something we knew: The Hobbit
is shorter than The Lord of The Rings
, but slightly surprises me when it shows so clearly that The Silmarillion
is almost half the length than LOTR
. Especially because the reader does not share that perception.
Maybe the readability differences could be attributed to the originality index? That is an index that I "invented", taking the number of unique words for each book and dividing it by the total word count. That would provide us with another way of comparing the books. But the originality index chart is surprising as well. I expected The Hobbit
to have the lowest index, since that was the book that I perceived as easiest to read; in fact I even thought it was too children-oriented at points. But I was wrong. Proportionally, it is the most original book, and according to this chart, The Silmarillion
would be only a bit less enjoyable than LOTR
, which with only a 3% index, should be a bore.
My hypotheses were not being proved right, because LOTR
is not a bore!
Could it be that I had taken into account the stop words but I should have not? I am referring to common English words such as the, and, of... -- which are the most frequent in these works! On one hand I was very tempted to execute again the program, excluding those words. On the other hand, I did not believe it could be a good idea, since when we read a book, we are reading the stop words as well. We are not one of those rudimentary search engines who need to filter information out in order to distinguish keywords! If I removed those words from the text, the results would correspond to entirely different books.
Still, I decided to build a simple chart comparing the proportion of stop words vs. non stop words. Again, the results were surprising. One would expect The Silmarillion
to have more filler text, but it was quite the contrary, with The Hobbit
being the richest in stop words. In any case, the differences between books were not very significative.
I ran another quick test (not pictured in this page) where I built these charts for Dracula
instead of LOTR
. That returned a very different set of results on every chart, so maybe instead of using these indices to compare books of the same author, they could be used to compare books of a known authors versus anonymous books -- that way we could guess who was the author of a book or piece of text!
And here end the most classical-academic of my speculations about Tolkien. I was satisfied with refuting that reviewer regarding the overuse of 'and', and had also found some interesting surprises. I could think of more indices to be calculated: the proportion of verbs, adverbs, adjectives, nouns and etc; types of used tenses, type of constructions... but if I really wanted to get serious with this whole text analysis business, that would require way more time and resources than building a few charts and speculating about them.
So I decided I would try to make something beatiful with the data instead :-)
1: Growing circular histogram
Plain histograms are slightly boring, so I built one which showed the most common words around a circle, with the top ones being propelled out of their orbit by some sort of spikey-bars. Also, text opacity is directly proportional to word count (in other words, less frequent words are more transparent). This creates that sort of subtle nebulae around the circle which you might appreciate depending on how your contrast settings are. These charts are simple-looking but I find them quite attractive when in movement:
Here are the links to The Lord of The Rings and The Silmarillion videos too.
2. Graphical representation of words frequency

All words on the books. Frequency is represented by font size, colours are randomly choosen. The aim is to fill all available space; that means even spaces inside letters as well.
Watching this one run and seeing almost all spaces being filled with words is highly amusing!
Here are the links to The Hobbit and The Silmarillion videos too.
The process
I initially began with something similar to the well known tag-cloud styles of charts:
But it didn't look very aesthetically pleasing. Even drawing a copy of each word, in white, before drawing the actual word, didn't make things easier to read. I thought it would be better to try and add some intelligence into the mix. So here's my first attempt at building an algorithm that would fill areas while avoiding gaps:
The upper half is the debug area, showing the pixels which are being tested. Each time a pixel is tested its colour changes, randomly. New rectangles are randomly generated and the algorithm makes room for each one of them, trying to minimize "waste". When there is no room for the new rectangle, it is simply rejected. The bottom half is the actual result (the rects). Their colour is random too.
Here's another example, where some areas have already been pre-filled with red rectangles. The algorithm takes that in account and allocates the new rects somewhere else. Nothing specially fancy, but it was important to test/demonstrate that the algorithm could work in more situations and scenarios than with an empty initial canvas :)
And here's another test where the polygons that we try to fit are squares instead. I like its 8-bit looks!
Once the area allocation was sorted out, I began placing text instead of just rectangles. This is the first test, trying a random order for the words. Note how some pixels change randomly, it's because they are being tested and I left some colours 'on' for debugging - they are not meant to appear in the final output:
But there was still a lot of unused space, specially around the biggest words, due to the way I was calculating the space used by each block of text. So I added another step: each time a word was drawn to the screen, that area would be evaluated and the "used space" array would be updated, setting a pixel as "occupied" only if it had some real text in it. Since I know how big each block is, I do not need to evaluate the entire screen on each pass. This allowed me to get words inside words, as shown. Finally, I also changed the algorithm to look for places randomly, so that the words get a bit more scattered and not packed on top of the screen instead:
In that last step, the differences in size between words are still too exaggerated, so I used the square root of the size to somehow smooth those differences and give some words the chance to show up in the chart, insted of outputting them at microscopic sizes.
3. Word relationships

And now for something completely different™!
Up until now I had been just drawing and considering isolated words, completely taken out of their context. But when parsing the text files I was also building lists of the most popular words that follow each word. So I wondered how could I draw this information. I first considered a tree, but the recursion ghost was hovering too close to me, so I decided to try another approach: drawing a circle with the top N words around it, and then drawing a line from a word to the top five words that follow it. Actually this chart looks a lot like the first one, but the action happens inside ;-)
This chart has a certain something. Not sure about you, but it reminds me a lot to Moon pictures. And obviously, once that space mood had been set in my mind, nothing could stop me from rendering a version in which the words create something like an eclipse before disappearing in the space void:
I also made a version without text, with the lines only. I find that one specially beatiful, even poetic, in a way.
And for The Silmarillion
we go back to the black and white scheme:
The tools
I used Processing + Eclipse + ffmpeg. What made me choose Processing over pure OpenGL was its font support, which I have not implemented in my own code base. But I was using Java Generics (for operations like sorting, hashing) and they did not work too well with the Processing Development Environment, so I set up Eclipse to use Processing - quite a fairly easy process. The videos are generated with ffmpeg, once each frame has been output as a PNG file.